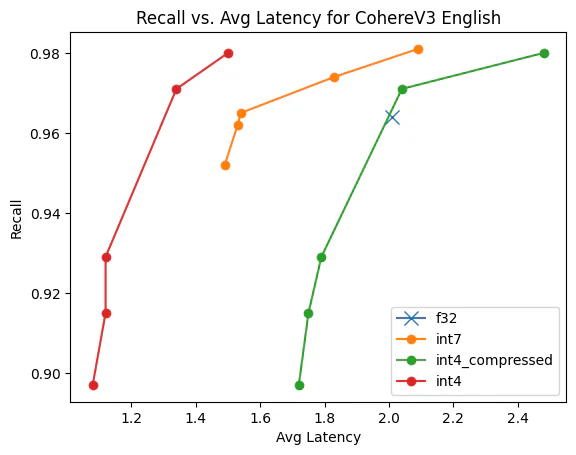
数据统计在深度学习中的重要性
- 1. 数据统计的基础概念
- 2. 数据统计在TensorFlow中的实现
- 2.1 张量范数
- 2.2 归约操作
- 2.2.1 计算最大值和最小值
- 2.2.2 计算均值和总和
- 2.3 损失函数的统计
- 2.3.1 均方误差
- 2.4 模型性能的统计
- 2.4.1 准确率
- 3. 数据统计在模型训练中的应用
- 3.1 学习率调整
- 3.2 早停(Early Stopping)
- 3.3 超参数优化
- 4. 结合实际案例的深入分析
- 4.1 数据预处理
- 4.1.1 数据清洗
- 4.1.2 数据标准化
- 4.2 模型构建与训练
- 4.2.1 损失函数的选择
- 4.2.2 性能指标的计算
- 4.3 结果分析与模型优化
- 4.3.1 性能瓶颈分析
- 4.3.2 模型调参
- 5. 总结
在深度学习的研究与应用中,数据统计扮演着至关重要的角色。它不仅帮助我们理解数据的特征,还能优化模型的训练过程,提高模型的泛化能力。本文将探讨数据统计在深度学习中的重要性,并展示如何在TensorFlow中实现关键的数据统计操作。
1. 数据统计的基础概念
数据统计通常包括数据的聚集、整合和分析,以得出有意义的结论。在深度学习中,数据统计用于以下几个方面:
- 理解数据分布:通过统计数据的均值、中位数、方差等,了解数据的一般特征。
- 特征缩放:标准化或归一化数据,以消除不同量级的特征对模型的影响。
- 损失函数的计算:使用统计方法计算模型的损失,如均方误差(MSE)或交叉熵。
- 性能评估:利用准确率、召回率等统计指标评估模型性能。
2. 数据统计在TensorFlow中的实现
TensorFlow提供了多种工具来执行数据统计,包括tf.reduce_*系列操作和tf.norm等。
2.1 张量范数
张量范数是衡量张量大小的一种方法,常用于正则化网络权重,避免过拟合。
import tensorflow as tf
# 假设x是一个张量
x = tf.random.normal([2, 2])
# 计算L2范数
l2_norm = tf.norm(x, ord=2)
2.2 归约操作
tf.reduce_*操作可以对张量进行归约,计算特定维度的统计值。
2.2.1 计算最大值和最小值
# 计算张量在某一维度上的最大值和最小值
max_value = tf.reduce_max(x, axis=0)
min_value = tf.reduce_min(x, axis=0)
2.2.2 计算均值和总和
# 计算张量的均值和总和
mean_value = tf.reduce_mean(x, axis=1)
sum_value = tf.reduce_sum(x, axis=1)
2.3 损失函数的统计
在训练模型时,损失函数的统计是关键步骤。
2.3.1 均方误差
# 假设y是真实值,y_pred是预测值
y = tf.constant([1, 2, 3])
y_pred = tf.constant([1.1, 2.9, 2.5])
# 计算均方误差
mse = tf.reduce_mean(tf.square(y_pred - y))
2.4 模型性能的统计
模型性能的统计通常在测试阶段进行。
2.4.1 准确率
# 假设pred是预测类别,label是真实类别
pred = tf.constant([0, 2, 1])
label = tf.constant([0, 1, 1])
# 计算准确率
accuracy = tf.reduce_mean(tf.cast(tf.equal(pred, label), tf.float32))
3. 数据统计在模型训练中的应用
数据统计不仅用于评估模型性能,还直接影响模型的训练过程。
3.1 学习率调整
通过监控验证集上的性能,可以调整学习率,优化训练过程。
3.2 早停(Early Stopping)
使用验证集的损失变化作为停止训练的依据,防止过拟合。
3.3 超参数优化
利用统计数据来选择最佳的网络结构和超参数。
4. 结合实际案例的深入分析
为了深入理解数据统计在深度学习中的重要性,我们可以通过一个具体案例来展示其应用。
4.1 数据预处理
在训练任何模型之前,数据预处理是必要的步骤。
4.1.1 数据清洗
移除异常值和处理缺失值。
4.1.2 数据标准化
使数据具有零均值和单位方差。
4.2 模型构建与训练
构建模型并使用数据统计来监控训练过程。
4.2.1 损失函数的选择
根据问题类型选择合适的损失函数。
4.2.2 性能指标的计算
使用统计方法计算准确率、召回率等。
4.3 结果分析与模型优化
使用统计数据来分析模型性能,指导模型优化。
4.3.1 性能瓶颈分析
通过统计数据识别模型性能的瓶颈。
4.3.2 模型调参
根据统计结果调整模型参数。
5. 总结
数据统计是深度学习不可或缺的一部分,它涉及到数据预处理、模型训练、性能评估等多个方面。通过TensorFlow等工具,我们可以方便地实现数据统计,从而提升模型的性能和泛化能力。